
पाइथन में प्राकृतिक भाषा संसाधन, भाग : 5. पद-विच्छेदन/पार्सिंग (Parsing)
§
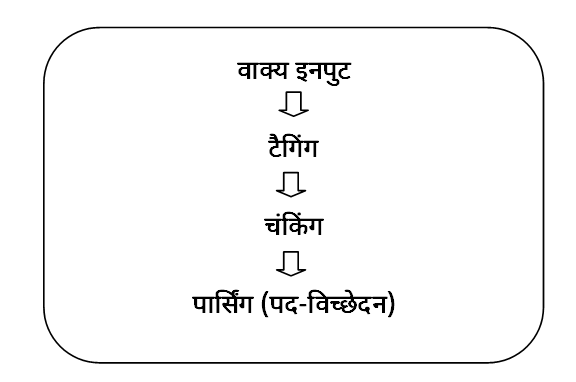
किसी
वाक्य को उसकी संरचना के अनुसार विश्लेषित करने की प्रक्रिया पद-विच्छेदन है।
§
पद-विच्छेदन
के लिए सर्वप्रथम वाक्य की टैगिंग करना आवश्यक होता है।
§
टैगिंग
के बाद चंकिंग (पदबंध-चिह्नन) का कार्य किया जाता है।
§
इसके
पश्चात पद-विच्छेदित वाक्य निर्मित होता है। अतः इसे क्रमानुसार निम्नलिखित प्रकार
से देखा जा सकता है-
पाइथन में पद-विच्छेदन/पार्सिंग
इसके लिए निम्नलिखित कोड करें-
!pip install nltk
!pip install indic-nlp-library
import nltk
nltk.download('punkt')
import nltk
from nltk.tokenize import word_tokenize
from indicnlp.tokenize import indic_tokenize # Use Indic NLP for better
Hindi tokenization
# Set up Indic NLP resources
import os
os.environ["INDIC_RESOURCES_PATH"] = "/path/to/indic_nlp_resources"
text = "My son is a very good boy"
# Tokenize the text
words = indic_tokenize.trivial_tokenize(text)
# Perform parsing (example:
chunking)
grammar = r"""
NP:
{<NN.*><JJ.*>*} # Noun Phrase
VP:
{<VB.*><NP|PP>*} # Verb Phrase
PP: {<IN><NP>}
# Prepositional Phrase
"""
cp = nltk.RegexpParser(grammar)
tree = cp.parse(nltk.pos_tag(words))
print(tree)
हिंदी पाठ के लिए :
नोट : अभी नहीं हो रहा है
!pip install nltk
!pip install indic-nlp-library
import nltk
nltk.download('punkt')
import nltk
from nltk.tokenize import word_tokenize
from indicnlp.tokenize import indic_tokenize # Use Indic NLP for better
Hindi tokenization
# Set up Indic NLP resources
import os
os.environ["INDIC_RESOURCES_PATH"] = "/path/to/indic_nlp_resources"
text = "मैं आज बाजार जा रहा हूँ।"
# Tokenize the text
words = indic_tokenize.trivial_tokenize(text)
# Perform parsing (example:
chunking)
grammar = r"""
NP:
{<NN.*><JJ.*>*} # Noun Phrase
VP:
{<VB.*><NP|PP>*} # Verb Phrase
PP: {<IN><NP>}
# Prepositional Phrase
"""
cp = nltk.RegexpParser(grammar)
tree = cp.parse(nltk.pos_tag(words))
print(tree)
NLTK Treebank से वाक्य का पद-विच्छेदन :
NLTK में उपलब्ध Treebanks का प्रयोग करते हुए पार्सिंग भी की जा सकती है। यहाँ ट्रीबैंक के पार्स किए हुए वाक्य को प्रोग्राम से जोड़कर दिखाया गया है-


No comments:
Post a Comment