
निकटस्थ अवयव विश्लेषण (IC Analysis)
हिंदी में इसे 'सन्निहित
घटक विश्लेषण' भी कहते हैं। इसका अंग्रेजी में पूरा नाम Immediate
Constituent Analysis है। इसका प्रतिपादन एल. ब्लूमफील्ड द्वारा
किया गया। यह वाक्य विश्लेषण की पद्धति है। वाक्य में शब्द या पद एक के बाद एक
क्रम से आते हैं। अतः उन्हें देखकर यह बताना कठिन है कौन-सा शब्द/पद वाक्य किस
दूसरे शब्द/पद से प्रकार्य की दृष्टि से जुड़ा हुआ है। ब्लूमफील्ड ने संरचना और
प्रकार्य की दृष्टि से आपस में जुड़े हुए शब्दों/पदों और पदबंधों को अलग-अलग
चिह्नित करने जो पद्धति विकसित की वही IC Analysis कहलाई।
इसमें सबसे पहले एक से अधिक उन शब्दों/पदों को एक साथ समूह में प्रदर्शित किया
जाता है, जो एक पदबंध का निर्माण करते हैं। इसके बाद सभी
पदबंधों को उद्देश्य और विधेय (subject and predicate) के
क्रम में आपस में जोड़ दिया जाता है।
कुछ वाक्यों में निकटस्थ अवयव विश्लेषण के
उदाहरण इस प्रकार हैं-

Rulon
Wells ने निकटस्थ अवयव विश्लेषण संबंधी कार्यों को आगे बढ़ाया है।
IC
Analysis की कुछ महत्वपूर्ण अवधारणाएँ
(क) परम घटक (Ultimate Constituent) : किसी रचना
के सबसे छोटे अर्थपूर्ण घटक को घटक कहते हैं।
(ख) आंतरिक संसक्ति (Internal Cohesion) : यह दो
घटकों के बीच पाए जाने वाली वह अवस्था है जिससे वह घटक आपस में जुड़े होते हैं।
(ग) आंतरिक भिन्नता (Internal diversity) : यह दो
घटकों के बीच पाए जाने वाले वह अवस्था है जिसके कारण वे घटक एक दूसरे से भिन्न
होते हैं।
(घ) स्वायत्तता (Independence) : किसी रचना के घटक परस्पर संबंध
होने पर इस प्रकार से स्वतंत्र होते हैं कि वे कहीं भी एक समूह में आ सकते हैं,
जैसे-
- मैंने एक पका आम खाया।
- एक पका आम बाजार में
नहीं मिलता।
- उसके साइकिल से गिरे हुए एक
पके आम को किसी ने उठा लिया।
उपर्युक्त वाक्यों में 'एक पका आम' पदबंध इस प्रकार से स्वायत्त है कि वह कहीं भी एक समूह के रूप में आने की
क्षमता रखता है।
SK Verma और N.
Krishnaswamy ने Modern linguistics : An Introduction
(1989) में बताया है कि निकटस्थ अवयव विश्लेषण में प्रस्तुति के लिए
कई प्रकार के मॉडलों का प्रयोग किया जाता है। उनके द्वारा दर्शाए गए कुछ मॉडलों को
इस प्रकार से देख सकते हैं -

इस क्रम में उन्होंने आगे यह भी कहा है कि वाक्य रचना में आने वाले निकटस्थ अवयवों को उनके लेबल के माध्यम से भी समझाया जा सकता है। ये लेबल हेड, क्वालीफायर लेबल हो सकते हैं अथवा विविध प्रकार के पदबंधों के भी लेबल हो सकते हैं, जिन्हें उनके द्वारा दिए गए निम्नलिखित चित्रों में देखा जा सकता है-


इसी प्रकार निकटस्थ अवयवों को ट्री डायग्राम के
माध्यम से भी दिखाया जा सकता है जिसे हम विकिपीडिया के निम्नलिखित चित्र से देख
सकते हैं-
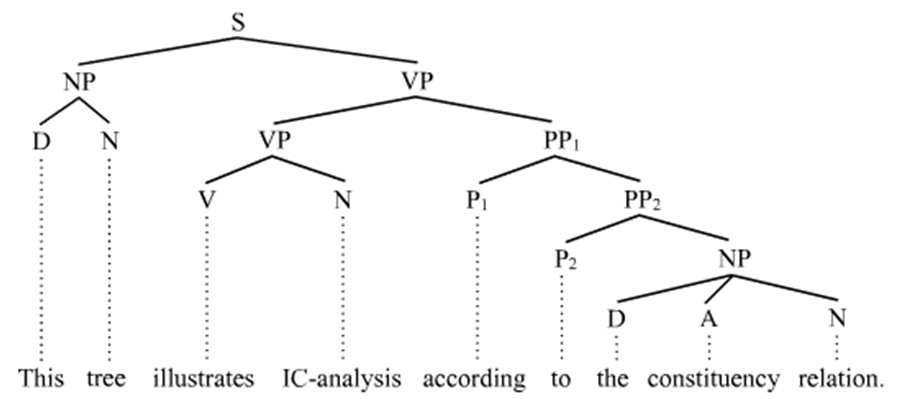
(संदर्भ- https://en.wikipedia.org/wiki/Immediate_constituent_analysis) इस प्रकार हम देख सकते हैं कि निकटस्थ अवयव
विश्लेषण पद्धति के माध्यम से विभिन्न प्रकार की वाक्य रचनाओं में आने वाले घटकों
का विश्लेषण विविध प्रकार से किया जा सकता है। यद्यपि इस विश्लेषण पद्धति की अपनी
सीमाएं रही हैं, जिनकी ओर संकेत बाद के भाषावैज्ञानिकों
द्वारा किया गया है और नए मॉडलों को भी प्रस्तावित किया गया है, जिनमें रूपांतरक प्रजनक व्याकरण, निर्भरता व्याकरण,
कारक व्याकरण आदि प्रमुख रहे हैं। रूपांतरक प्रजनक व्याकरण का तो
उदय ही संरचनावादी विश्लेषण पद्धति को चुनौती देते हुए हुआ है जिसके बारे में हम
आगे चर्चा करेंगे।
किसी वाक्य में आए घटकों के विश्लेषण में
निर्भरता व्याकरण (Dependency
Grammar - DG) आधारित विश्लेषण पद्धति और निकट अष्ट अवयव विश्लेषण (IC
Analysis) आधारित विश्लेषण पद्धति के माध्यम से बनने वाले वृक्ष
आरेख में अंतर को विकिपीडिया के निम्नलिखित चित्र की
सहायता से देख सकते हैं-

विनीत चैतन्य और राजीव सिंघल ने ‘Natural Language Processing : A Paninian Perspective’ में
पाणिनीय मॉडल को आधार बनाते हुए इस प्रकार की संरचनाओं को कारक आधारित प्रकार्यों
को जोड़ते हुए भी दिखाया है, जिसे निम्नलिखित चित्र में देखा
जा सकता है-

(1996,
पृ. 16)
इसी
प्रकार एक अन्य उदाहरण देख सकते हैं-

K1 = karta, K2 = Karma, K3 = Karan

No comments:
Post a Comment