

Saturday, September 23, 2023
नई भाषा सीखने में लगने वाला समय
 प्रोफेसर, केंद्रीय हिंदी संस्थान, आगरा
Professor, Kendriya Hindi Sansthan, Agra
(Managing Director : Ms. Ragini Kumari)
प्रोफेसर, केंद्रीय हिंदी संस्थान, आगरा
Professor, Kendriya Hindi Sansthan, Agra
(Managing Director : Ms. Ragini Kumari)
Thursday, September 14, 2023
पाइथन : एक परिचय (Python : An Introduction)
पाइथन : एक परिचय (Python : An Introduction)
पाइथन वर्तमान दौर (21वीं शताब्दी के दूसरे दशक) की सबसे
प्रसिद्ध भाषा है। प्रोग्रामिंग के क्षेत्र में कार्य कर रहे लोगों द्वारा इसके कई
कारण बताए जाते हैं, जैसे- यह भाषा अन्य प्रोग्रामिंग भाषाओं की
तुलना में अधिक सरल है; इसका उपयोग विविध प्रकार के
सॉफ्टवेयर के विकास, जैसे- web development,
software development और Scientific application आदि किसी में भी किया जा सकता जाता है। वर्तमान दौर की अनेक बड़ी कंपनियाँ, जैसे- Google, Yahoo, Quora, Pinterest और
Spotify आदि इसका व्यापक स्तर पर उपयोग कर रही हैं। इसलिए
पाइथन भाषा सीखना इन सभी जुड़ने के लिए एक अच्छा विकल्प सिद्ध हो सकता है।
Python एक ‘general purpose
programming language’ है। इसका कारण है कि इस भाषा में App
development, Website building, Machine learning, Data analysis, Web scraping और Natural language processing आदि सभी कार्य किए
जाते हैं। यह एक Object-oriented और High level
programming language है। यह एक interpreted language है। अर्थात पाइथन भाषा में लिखे गये program के कोड को
पहले compile करने की जरूरत नही पड़ती है। इसमें कंपाइलर की
जगह इंटरप्रेटर का प्रयोग होता है। पाइथन भाषा में modules और
packages का प्रयोग किया जाता है। इसका लाभ यह है कि किसी python
program को एक modular style में design
किया जा सकता है और इसके code का निर्बाध रूप
से दूसरे project में पुनः उपयोग किया जा सकता है।
पाइथन के नवीन संस्करण
· Python 3.0 – December 3, 2008
· Python 3.1 – June 27, 2009
· Python 3.2 – February 20, 2011
· Python 3.3 – September 29, 2012
· Python 3.4 – March 16, 2014
· Python 3.5 – September 13, 2015
· Python 3.6 – December 23, 2016
· Python 3.7 – June 27, 2018
· Python 3.8 – October 14, 2019
पाइथन इंस्टॉल करना
पाइथन इंस्टॉल करने के लिए गूगल सर्च इंजन में ‘install python’ सर्च करें या https://www.python.org/downloads/
वेबसाइट पर जाएँ। यहाँ आपको ‘Download the latest version
for Windows’ का विकल्प मिलेगा। इसके साथ-साथ अन्य ऑपरेटिंग सिस्टम
पर भी इंस्टॉल के लिए लिंक दिए रहते हैं। आप अपने ऑपरेटिंग सिस्टम के अनुसार
डाउनलोड कर सकते हैं।
पाइथन और अनाकोंडा (Python and
Anaconda)
‘Anaconda’ Python और R प्रोग्रामिंग भाषाओं के लिए एक निःशुल्क और open-source
distribution है। इसके अंतर्गत Python interpreter के साथ-साथ machine learning और data science
के बहुत से पैकेज आते हैं। इन पैकेजों की आवश्यकता हमें प्रोग्राम
बनाने के समय पड़ती ही रहती है। यदि हम चाहें तो प्रत्येक पैकेज को अलग-अलग इंस्टॉल
कर सकते हैं, किंतु इसमें बहुत अधिक समय जाता है और
सोच-विचार भी अधिक करना पड़ता है। अतः सभी प्रकार के पैकेजों को एक ही जगह पर
अनाकोंडा distribution को इंस्टॉल करके पाया जा सकता है।
पाइथन और IDE
IDE का पूरा नाम ‘integrated
development environment’ है। यह एक software suite होता है जो किसी प्रोग्राम के विकास के लिए आवश्यक टूल्स और परिवेश उपलब्ध
कराता है। IDE के माध्यम से development-related
tools को एक single framework के अंतर्गत लाया
जाता है, जिससे प्रोग्राम का निर्माण करना और कोडिंग करना
अत्यंत सरल हो जाता है।
पाइथन भाषा में प्रोग्रामिंग के लिए अनेक IDEs का प्रयोग किया जाता है, जिनमें से 04
प्रमुख इस प्रकार हैं-
1. JUPYTER LAB
2. JUPYTER NOTEBOOK
3. SPYDER
4. PYCHARM
सामान्यतः आरंभिक प्रोग्रामर JUPYTER NOTEBOOK का प्रयोग करते हुए पाइथन में
प्रोग्रामिंग करते हैं। आगे हम इसका या गूगल कोलैब (Google COlab) का प्रयोग करते हुए प्रोग्रामिंग सीखेंगे।
प्रोफेसर, केंद्रीय हिंदी संस्थान, आगरा
Professor, Kendriya Hindi Sansthan, Agra
(Managing Director : Ms. Ragini Kumari)
पाइथन में कोड लिखना, इनपुट और आउटपुट
कोड लिखना, इनपुट और आउटपुट
किसी भी प्रोग्रामिंग भाषा में कोडिंग करने के प्रारंभिक
चरण हैं-
· चर (variable) डिक्लेयर करना और उसमें मूल्य (value)
प्रदान करना।
· इनपुट देना।
· आउटपुट लेना।
इन कार्यों के लिए एक अंतरापृष्ठ (Interface) की आवश्यकता होती है। पाइथान में प्रोग्रामिंग के लिए JUPYTER NOTEBOOK या
गूगल कोलैब (Google COlab) या कोई और IDE खोलते हैं तो बहुत ही सरल अंतरापृष्ठ दिखाई पड़ता है। सामान्यतः इसमें
कोडिंग के लिए एक पंक्ति (line) इस प्रकार दिखाई पड़ती है-

इसे cell कहते हैं। इसी में
अपने प्रोग्राम का कोड लिखा जाता है। उस कोड में ही आउटपुट के लिए कमांड भी लिखते
हैं। किसी वैल्यू का आउटपुट लेने लिए उसके साथ ‘print’ का प्रयोग इस प्रकार से किया जाता है-
print (“”)
उदाहरण के लिए आगे ‘Hi’ का आउटपुट देखने के लिए निम्नलिखित कोड करेंगे-
print ("Hi")
ab लाइन के आरंभ में दिख रहे play बटन को क्लिक करके या ‘शिफ्ट+इंटर’ दबाकर कोड को रन करेंगे। इसके बाद आउटपुट इस प्रकार दिखाई पड़ेगा-

इसे Single inverted comma में भी लिखकर रन कर सकते हैं-

जब एक आउटपुट निर्मित हो जाता है तो आगे कोड के लिए फिर वही
लाइन बन जाती है, जो इसमें दिखाई पड़ रही है। आगे का कोड इस
लाइन में किया जा सकता है।
कई लाइनों का कोड लिखने के लिए इंटर का प्रयोग करने पर इसी
में दूसरी-तीसरी (अगली) लाइनों के लिए जगह बनती जाती है। इसमें सिंगल या डबल
इंवर्टेड कोमा के बीच लिखा हुआ ‘Hi’ वैल्यू है, जिसे किसी वैरिएबल में भी स्टोर किया जा सकता है। उदाहरण के लिए x = ("My name ") और y = (“ is Dhruwa”) नाम से दो वैरिएबल्स में वैल्यू स्टोर कर सकते हैं। फिर उन दोनों को जोड़कर
एक साथ आउटपुट इस प्रकार से ले सकते हैं-

इसमें पहले दो चर ‘x’ और
‘y’ डिक्लेयर किए गए हैं और उनमें क्रमशः ("My name") और (“ is Dhruwa”) के वैल्यूज दिए गए हैं। इसके बाद
print का प्रयोग करते हुए दोनों का योग आउटपुट के रूप में
प्राप्त किया गया है।
print (…) एक फंक्शन है, जिसका प्रयोग करते हुए चरों या मूल्यों का आउटपुट प्राप्त किया जाता है।
इसका जितनी बार चाहें उतनी बार प्रयोग कर सकते हैं। उदाहरण के लिए हम तीन वैरिएबल
इस प्रकार ले सकते हैं-
name = "Dhruwa"
age = 5
weight = 15.5
उपर्युक्त तीनों का आउटपुट लेने के लिए तीन बार print (…) का प्रयोग करना होगा। अतः इन्हें इस प्रकार से प्रिंट
किया जा सकता है-

इस प्रकार से कई लाइनों में कोड लिखकर रन किया जाता है अथवा
कई आउटपुट एक साथ लिए जाते हैं।
प्रोफेसर, केंद्रीय हिंदी संस्थान, आगरा
Professor, Kendriya Hindi Sansthan, Agra
(Managing Director : Ms. Ragini Kumari)
पाइथन में रनटाइम में इनपुट लेना
रनटाइम में इनपुट लेना
ऊपर के कोड में प्रत्येक वैरिएबल का मूल्य पहले ही कोड में
दे दिया गया है, जिसे रनटाइम में बदल नहीं सकते। किसी
वैरिएबल के मूल्य (वैल्यू) को रनटाइम में यूजर से भी लिया जा सकता है। इसके लिए input()
मेथड का प्रयोग किया जाता है। उदाहरण के लिए दो string
values को जोड़ने के लिए दूसरे वैरिएबल का इनपुट यूजर से प्राप्त
करने के लिए निम्नलिखित प्रकार से कोड करते हैं-

इसमें बॉक्स में मूल्य भरना है। भरने के बाद इंटर दबाने पर इस
प्रकार से आउटपुट प्राप्त होगा-

इसमें ‘is Dhara’ इनपुट है और ‘My Name is Dhara’ आउटपुट।
string के अलावा अन्य प्रकार के डेटा का इनपुट लेने के लिए उनका
प्रकार पहले ही देना होता है, जैसे int का इनपुट इस प्रकार से ले सकते हैं-

इसमें x का input यूजर से लिया गया है, जो यहाँ ‘10’ है। इसके बाद ‘y’ की वैल्यू को इसमें जोड़कर प्रोग्राम
द्वारा आउटपुट दिया गया है।
इसमेंआउटपुट चिह्न के आगे तीन लाइनें दिखाई पड़ रही हैं, जिनमें से पहली लाइन ‘इनपुट’ वाली है, जिसके आगे मैंने ‘Mohan’ टाइप किया था। उसके नीचे की दो लाइनें आउटपुट हैं,
जो x और y के मूल्य (वैल्यूज) हैं।
प्रोफेसर, केंद्रीय हिंदी संस्थान, आगरा
Professor, Kendriya Hindi Sansthan, Agra
(Managing Director : Ms. Ragini Kumari)
पाइथन में एकसाथ कई Variables declare करना और values देना
एकसाथ कई Variables declare करना और values देना
पाइथन में एक ही लाइन में कई चरों (वैरिएबल्स) को डिक्लेयर
करके उन्हें मूल्य (वैल्यूज) दिए जा सकते हैं, जैसे-
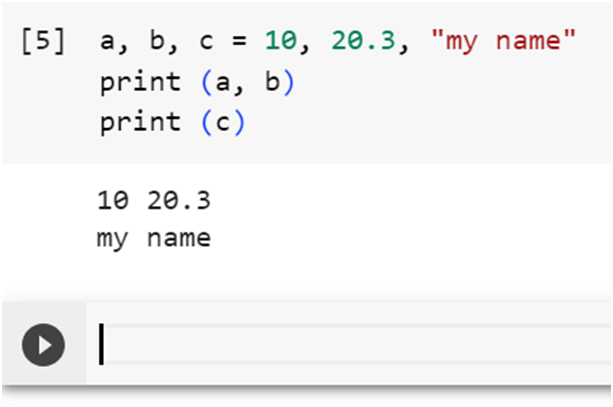
इसे अंग्रेजी में Assigning multiple
values to multiple variables कहते हैं।
इस प्रकार आपने देखा कि पाइथन में कोड कैसे लिखते हैं? इनपुट कैसे दिया जाता है और आउटपुट कैसे प्राप्त होता है?
प्रोफेसर, केंद्रीय हिंदी संस्थान, आगरा
Professor, Kendriya Hindi Sansthan, Agra
(Managing Director : Ms. Ragini Kumari)
पाइथन में Tokens
पाइथन में Tokens:
पाइथन भाषा में कोडिंग करते हुए एक कथन (statement) के अंतर्गत प्रयुक्त किया जाने वाला कोई भी punctuator
mark, reserved word और individual word ‘Token’ कहलाता है। इसे परिभाषित करते हुए कहा जा सकता है-
“Token is the smallest unit inside the given program.”
पाइथन में निम्नलिखित प्रकार के Tokens का प्रयोग किया जाता है-
· Keywords.
· Identifiers.
· Literals.
· Operators.
आगे इनकी विस्तार से चर्चा की जाएगी।
प्रोफेसर, केंद्रीय हिंदी संस्थान, आगरा
Professor, Kendriya Hindi Sansthan, Agra
(Managing Director : Ms. Ragini Kumari)
पाइथन में Comment लिखना
पाइथन में Comment लिखना
किसी भी प्रोग्रामिंग भाषा में प्रोग्राम का विकास करने के
लिए लंबे-लबे कोड लिखने पड़ते हैं, जिसके अलग-अलग
हिस्से अलग-अलग कार्य करते हैं। इसलिए उन हिस्सों की अलग-अलग पहचान या उनके द्वारा
किए जाने वाले कार्यों की सूचना देने के लिए comments लिखे
जाते हैं। इससे कई दिनों बाद भी प्रोग्राम खोलने पर comments
पढ़कर समझ में आ जाता है कि आगे के कोड द्वारा क्या किया जाना है। इसका दूसरा लाभ
यह भी है कि यदि हम अपना कोड किसी और को भी देते हैं तो उसे comments के माध्यम से कोड की संरचना को समझने में आसानी होती है।
पाइथन में comments
लिखने के लिए उनसे पहले # (हैश) का प्रयोग करते हैं। हैश के
बाद लिखी हुई बात comment होती है। कोड को रन करने पर comment में लिखी गई बात रन नहीं होती। comment लिखने को इस
प्रकार से देख सकते हैं-
इस कोड में comment
की तीन लाइनें हैं, जो क्रमशः अपने नीचे के कोड द्वारा किए
जा रहे कार्यों की सूचना दे रही हैं-
#get the items of 'dct'
print (dct)
#get the keys of 'dct'
print (dct.keys())
#get the values of 'dct'
print (dct.values())
यदि कई लाइनों का कमेंट लिखना हो तो triple quotes का प्रयोग करते हैं, जैसे-
''' hello
This Is my
Multipline
comment'''
प्रोफेसर, केंद्रीय हिंदी संस्थान, आगरा
Professor, Kendriya Hindi Sansthan, Agra
(Managing Director : Ms. Ragini Kumari)
पाइथन में डेटा टाइप (Data Types in Python)
पाइथन में डेटा टाइप (Data Types in Python)
कंप्यूटर में इनपुट के रूप में दी जाने वाली अथवा संसाधन के
बाद आउटपुट के रूप में प्राप्त होने वाली कोई भी सामग्री डेटा है। किसी भी डेटा को
संसाधित (process) और संग्रहीत (store) करने के लिए मेमोरी आवश्यकता पड़ती है। प्रोग्रामिंग में हम डेटा का इनपुट
सीधे-सीधे मशीन को देते हैं। इसलिए डेटा का इनपुट देते समय मशीन को पता होना चाहिए
कि इसके लिए कितनी मेमोरी locate करनी है। मेमोरी locate करने का काम कंपाइलर या इंटरप्रेटर द्वारा किया जाता है। प्रोग्रामिंग की
दृष्टि से डेटा के दो वर्ग हैं-
चर (variable) और अचर (constant)
‘अचर’ में सीधे-सीधे
मूल्य ही रहता है, इसलिए मूल्य के अनुसार इंटरप्रेटर मेमोरी locate कर देता है, लेकिन जब हम अपने कोड में चरों
(वैरिएबल्स) का प्रयोग करते हैं तो इंटरप्रेटर को पता नहीं होता कि इसके लिए कितनी
मेमोरी locate की जाए। इसलिए प्रत्येक प्रोग्रामिंग भाषा में
कुछ डेटा टाइपों का प्रयोग किया जाता है।
पाइथन भाषा में प्रयुक्त होने वाले प्रमुख डेटा टाइप
निम्नलिखित हैं-
(क) Numbers
(ख) String
(ग) List
(घ) Tuple
(ङ) Dictionary
आगे इन्हें विस्तार से देखते हैं-
- पाइथन
में numeric डाटा टाइप
- पाइथन
में String डाटा टाइप
- पाइथन
में List डाटा टाइप
- पाइथन
में Tuple डाटा टाइप
- पाइथन
में Dictionary डाटा टाइप
प्रोफेसर, केंद्रीय हिंदी संस्थान, आगरा
Professor, Kendriya Hindi Sansthan, Agra
(Managing Director : Ms. Ragini Kumari)
पाइथन में numeric डाटा टाइप
Numbers
संख्याओं वाले मूल्यों (numeric values) को संग्रहीत करने वाले डेटा टाइप को Number कहते
हैं। इसके अंतर्गत चार प्रकार के संख्यात्मक मूल्य आते हैं-
· int (पूर्णांक 100, 12,
292 आदि)
· long (बड़े मूल्य वाले पूर्णांक, जैसे- 208090800, -0x3429292L
आदि)
· float (दशमलव वाली संख्याएँ,
जैसे- 2.3, 19.302, 17.3 आदि)
· complex (जटिल संख्याएँ, जैसे-
4.12j, 5.0 + 2.1j आदि)
Number डेटा टाइप का वैरिएबल डिक्लेयर करने
के लिए उसका टाइप- int, long, float आदि लिखने की आवश्यकता
नहीं होती, केवल वैरिएबल नाम लिखकर मूल्य दे देने से
इंटरप्रेटर स्वयं डेटा प्रकार निर्धारित कर लेता है, जैसे-
a = 5
b = 3.5
पाइथन कोड में ये लाइनें लिखते ही इंटरप्रेटर a को int और b को
float डेटा टाइप के अंतर्गत रख देगा। किसी वैरिएबल को कौन-सा डेटा
टाइप assign किया गया है, इसे देखने के
लिए निम्नलिखित कोड कर सकते हैं-

इसमें पहली दो लाइनों में a
और b चर (वैरिएबल) डिक्लेयर किए गए हैं, जबकि बाद की दो लाइनों में ‘print()’ का प्रयोग
करते हुए उसके अंदर ‘type()’ मेथड का प्रयोग किया गया है। इसके
द्वारा हमें a और b के डेटा टाइप का
पता चलता है, जिसका डिक्लेयर करते समय कोई उल्लेख नहीं किया
गया है।
इसकी तुलना यदि आपको C, C++ अथवा
C# जैसी भाषाओं का ज्ञान हो, तो देख सकते हैं
कि वहाँ कोड इस प्रकार लिखना पड़ता है-
int a = 5;
float b = 3.5;
अतः पाइथन में कोड लिखना उसकी तुलना में सरल है। वैसे हम
चाहें तो डेटा टाइप के साथ भी चर (वैरिएबल) डिक्लेयर कर सकते हैं। इसके लिए पहले डेटा
टाइप का नाम लिखकर उसके बाद छोटे कोष्ठक में वैल्यू लिखते हैं। यदि आप डेटा टाइप
का पहले ही उल्लेख कर देते हैं तो इंटरप्रेटर उसी के अनुसार चर (वैरिएबल) का मूल्य
बना लेता है। उदाहरण के लिए निम्नलिखित कोड देखें-

इसमें आप देख सकते हैं कि मैंने a और b चरों (वैरिएबल्स) को डिक्लेयर करते
समय उनका डेटा टाइप भी दे दिया है। डिक्लेयर करते समय दोनों में एक ही मूल्य (5)
दिया गया है, फिर आउटपुट में डेटा टाइप के अनुसार a के लिए 5.0 का प्रयोग किया गया है, क्योंकि यह एक float
टाइप का चर (वैरिएबल) है।
प्रोफेसर, केंद्रीय हिंदी संस्थान, आगरा
Professor, Kendriya Hindi Sansthan, Agra
(Managing Director : Ms. Ragini Kumari)
पाइथन में String डाटा टाइप
String
string को ‘sequence of characters
represented in the quotation marks’ के रूप में परिभाषित किया जाता
है। अर्थात एक या एक से अधिक वर्णों का समूह string के
अंतर्गत आता है। पाइथन में string के लिए single या double quotes का प्रयोग किया जा सकता है। वैसे
सामान्यतः लोग double quotes के प्रयोग की ही सलाह देते हैं।
टाइप किए हुए पाठ के संसाधन में String handling की केंद्रीय भूमिका रहती है। अतः प्राकृतिक
भाषा संसाधन (NLP) के लिए अध्येता को किसी भी प्रोग्रामिंग
भाषा में String handling बहुत अच्छे से आनी चाहिए। पाइथन
में String handling के लिए बहुत inbuilt functions
and operators हैं, जिनकी विस्तृत चर्चा एक
स्वतंत्रउपशीर्षक में आगे की जाएगी। यहाँ हम केवल डेटा टाइप के रूप में string का परिचय कर रहे हैं।
निम्नलिखित उदाहरण में string के
लिए वैरिएबल डिक्लेयर करने और उसे प्रिंट करने की प्रक्रिया दिखाई जा रही है-

यहाँ पर name नामक वैरिएबल लेकर
उसमें double quotes का प्रयोग करते हुए "mohan" वैल्यू दिया गया है। इससे इंटरप्रेटर ने इसे string
के रूप में लिया है और इसके वैल्यू को आउटपुट के रूप में दिया है। हम double
quotes की जगह single quotes का भी प्रयोग कर
सकते हैं, जैसे-

string handling के मामले में याद रखना चाहिए कि + ऑपरेटर का प्रयोग करने पर एक से अधिक strings को concatenate किया जाता है। अर्थात पाइथन में "hello"+"
python" लिखकर प्रिंट किया जाएगा तो "hello
python" आउटपुट आएगा, जैसे-

दो अलग-अलग वैरिएबल्स में string values को रखकर उनके साथ + ऑपरेटर का प्रयोग करके भी यह आउटपुट प्राप्त किया जा
सकता है, जैसे-

इसी प्रकार * ऑपरेटर
का प्रयोग पुनरुक्ति (repetition) या दुहराव के लिए किया
जाता है। एक string value को जितनी बार प्रिंट करना हो, उस वैल्यू के साथ * ऑपरेटर का प्रयोग करते हुए उतनी संख्या लिख दी जाती
है, जैसे- "Python " *2 का
आउटपुट "Python Python " होगा, जबकि "Python " *3 का आउटपुट "
Python Python Python " होगा-
 प्रोफेसर, केंद्रीय हिंदी संस्थान, आगरा
Professor, Kendriya Hindi Sansthan, Agra
(Managing Director : Ms. Ragini Kumari)
प्रोफेसर, केंद्रीय हिंदी संस्थान, आगरा
Professor, Kendriya Hindi Sansthan, Agra
(Managing Director : Ms. Ragini Kumari)
Subscribe to:
Posts (Atom)